



Photo by Arseny Togulev on Unsplash
BERT Language Model and Transformers
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM).


Introduction
In this tutorial, we will provide a little background on the BERT model and how it works.
The BERT model was pre-trained using text from Wikipedia. It uses surrounding text to establish its context and can be fine-tuned with question-and-answer datasets.
What is BERT?
Bidirectional Encoder Representations from Transformers, aka BERT, is an open-source machine learning framework for NLP. It’s designed to help computers understand the meaning of ambiguous language in a large text corpus. But how can BERT do such tasks?
BERT is based on Transformer, a deep learning model where every output element is connected to every input element, and the weightings between them are dynamically calculated based on their connection. In NLP, this is a process called attention:
…when the model is trying to predict the next word it searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts next word based on context vectors associated with these source positions and all the previous generated target words.
Language models that arrived before BERT, such as Word2Vec, GloVe, ELMo, and ULMFiT, could only read text input sequentially (either left-to-right or right-to-left) but couldn’t do both simultaneously. Moreover, BERT is an entirely different (and more advanced) model, designed to read in both directions simultaneously. This capability that appeared with the introduction of Transformers is known as bidirectionality.
This bidirectional capability, which is BERT pre-trained, uses two different but related tasks: Masked Language Modeling and Next Sentence Prediction.
Masked Language Modeling (MLM) is a sub-research area of language modeling that involves understanding contextual information about words in a specific text. Its main goal is to make the model consider surrounding words by learning in which context words appear.

Figure 1: Screenshot of how the MLM masks words in a sentence (Image by Author)
In the above picture, the words in red are the current words that are masked during the MLM process, and the words in black are the words that work as their immediate surroundings.
In the third sentence, the “black fox jumped over the dog,” what would be an appropriate word if we remove the word jumped and have the sentence say “black fox _______ over the dog”?
To fill in the blanks, we can consider words like bounced, dropped, fallen, etc. However, we cannot say ate, drove, chair, or other random words.
Therefore, it must understand the language structure to ensure the model learns which word is appropriate. As modelers, we need to help it do so. We only need to give the model inputs with blanks as a “token” <MASK> and the word that should be there.
How Does BERT Work?
To see how the MLM works in code, let’s install the following libraries, which are at the distance of a pip install <library>
Tensorflow & Keras: Both are some of the most commonly used libraries for DL purposes in Python. We will use them for training our model.
Hugging Face Transformers: This library is one of the recent developments in the open-source community. It has a massive database of trained models and datasets we can use in any codebase. In this tutorial, we will use one of them, the pre-trained BERT model.
NLTK: A simple text processing library used for NLP purposes. We will use it for data pre-processing before passing it to the model.
Seaborn and Matplotlib: These will be used for plotting our training performance.
Google Colab is a great option to work with libraries like Tensorflow. It performs better using the GPU instead of the CPU, so we will be working in a Colab Notebook this time.
Loading, Labeling, and Tokenizing the Data
After we have installed and imported all the required resources into the notebook, we will use one of the datasets provided in the installation, the text from the book “Moby Dick” by Herman Melville. This dataset is a public domain dataset from Project Gutenberg that comes installed in the nltk package. When you run the code below in the notebook, it will be downloaded in the same project directory:
!cp /root/nltk_data/corpora/gutenberg/melville-moby_dick.txt moby_dick.txt
Pre-processing the data involves removing stopwords and punctuation signs and converting the words into tokens, which is the format that BERT needs. Then, we will use the tokenizer that Hugging Face provides.
After that, we loaded into the notebook some helper functions that will work for data processing and tokenization, and we read only the first 1000 lines of the text:

Loading The Masked Language Model
We use the model from the Transformers library directly. Working with the uncased model will convert all text into lowercase.

We will later use the previously defined model, with the help of some defined functions, to train and predict the tokens in a sentence.
Creating a Mask
In a masked language model, such as BERT, creating a mask refers to replacing some of the tokens in the previously defined inputs with a special token called the [MASK] token. In this case, we have set it as 103.
Then, during training, a certain percentage of the input tokens are randomly selected and replaced with the [MASK] token. The model is then trained to predict the original token based on the surrounding context.
Prediction
The final purpose of training a language model is to be able to use it for predicting blank spaces in the text. As we stated before, the predictions are based on the surrounding context. After we define a mask in the code, we are ready to give the model a practice exam. Since we fine-tuned the model over the book “Moby Dick,” we will provide it with some sentences to predict blank spaces on it:
query_list = ["And what thing soever [MASK] cometh within the chaos",
"Scarcely had we [MASK] two days on the sea",
"He visited this [MASK] also with a view of [MASK] horse-whales"]
By using the functions previously defined, it will predict the [MASK] on the sentences:
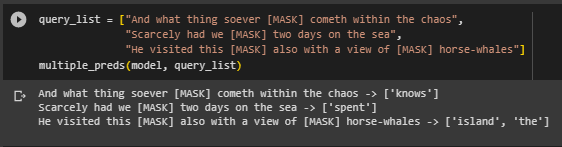
As we can notice, the [MASK] in the sentences was replaced by a word that, even though it’s not exactly the same in the original text, still performs quite well even with short training.
Final Words
In summary, the BERT model is a powerful language model that uses a masked language modeling strategy to learn which word is appropriate in context, considering the surrounding words in the text. By masking a portion of the input text, the model is forced to learn a general understanding of the language and its context rather than relying on memorization of specific phrases or sentences.
The above-described approach has been proven to be highly effective in a wide range of NLP tasks and has contributed to significant advances in this field.
BERT is currently used in Google to optimize the interpretation of user search queries.
References
Lutkevich, B. (2020, January). What is BERT (Language Model) and How Does It Work? SearchEnterpriseAI. https://www.techtarget.com/searchenterpriseai/definition/BERT-language-model